728x90
LCS(Longest Common Subsequence)
- 공통 부분 문자열 중 가장 길이가 긴 문자열을 말하는 ‘최장 공통 부분 수열’이라고 한다.
- LCS는 최장 공통 문자열이라고도 불리는데 그 차이는
- 최장 공통 부분 수열은 문자열 안의 공통된 문자를 다 구한다
- 최장 공통 문자열은 문자열 안의 공통된 문자 중 연속된 문자를 구한다.
- 다이나믹 프로그래밍(DP)방식으로 구현된다.
LCS - Substring(최장 공통 문자열)
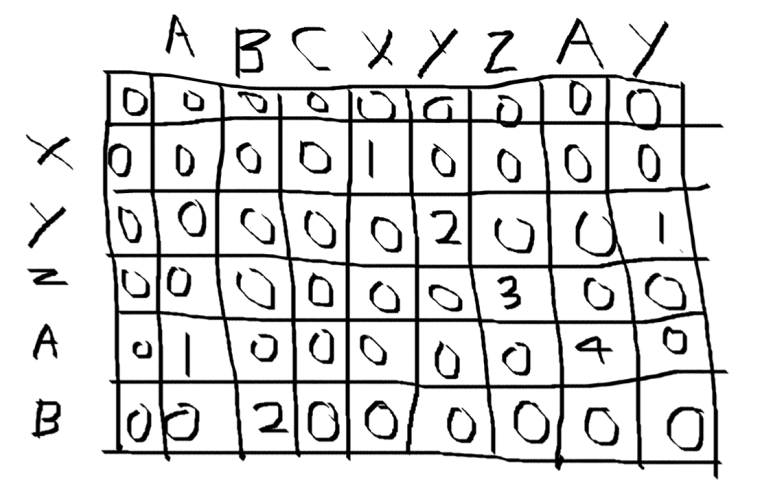
- 두 문자열을 비교하는 표인데 이 때, 반드시 두 문자열의 가장 앞 칸은 0으로 해야 한다.
- 만약 두 문자열 중 어느 것이라도 첫 번째 문자가 일치하면 그 좌표의 -1 좌표에서 값을 참조해야 하는데 [0, 0]이면 앞 칸이기 때문에 음수로 참조하게 되고 에러가 발생한다.
- 최장 공통 문자열은 같은 문자 만을 비교하며, 같은 문자가 있는 좌표에 1을 입력한다. 그리고 다음 문자를 비교할 때 연속적으로 문자가 비교되면 누적을 해 2를 입력한다.
- 이런 식으로 누적 문자열을 쌓아서 가장 많은 수의 문자열을 출력한다.
- 최장 공통 문자열 점화 식

- 예시 코드
def LCSubStr(X, Y):
# 문자열 두 개를 m, n에 저장
m = len(X)
n = len(Y)
# m+1 행, n+1 열의 크기를 가진 2차원 리스트를 생성하고, 모든 셀의 값을 0으로 초기화
# X와 Y의 각 부분 문자열에 대한 가장 긴 문자열의 길이를 저장하는 데 사용
LCSuff = [[0 for k in range(n+1)] for l in range(m+1)]
# 가장 긴 문자열의 길이를 저장하는 변수
result = 0
# 가장 긴 문자열이 끝나는 인덱스를 저장하는 변수
end = 0
# 모든 좌표를 확인하는 반복문
for i in range(1, m+1):
for j in range(1, n+1):
# 현재 위치가 문자열의 시작점이면 LCSuff의 현재 셀 값을 0으로 설정
if (i == 0 or j == 0):
LCSuff[i][j] = 0
# X와 Y의 현재 문자가 같으면,현재 셀 값은 이전 셀의 값에 1을 더한 값이다.
# 이 값이 현재의 result보다 크면 result와 end를 갱신
elif (X[i-1] == Y[j-1]):
LCSuff[i][j] = LCSuff[i-1][j-1] + 1
if LCSuff[i][j] > result:
result = LCSuff[i][j]
end = i - 1
# X와 Y의 현재 문자가 다르면, LCSuff의 현재 셀 값을 0으로 설정
else:
LCSuff[i][j] = 0
# X에서 가장 긴 문자열을 추출하여 반환
return X[end-result+1 : end+1]
# 비교하는 두 문자열
X = 'ABCBDAB'
Y = 'BDCABC'
# 가장 긴 문자열을 출력
print('Longest Common Substring is', LCSubStr(X, Y))
LCS - Subsequence(최장 공통 부분 수열)
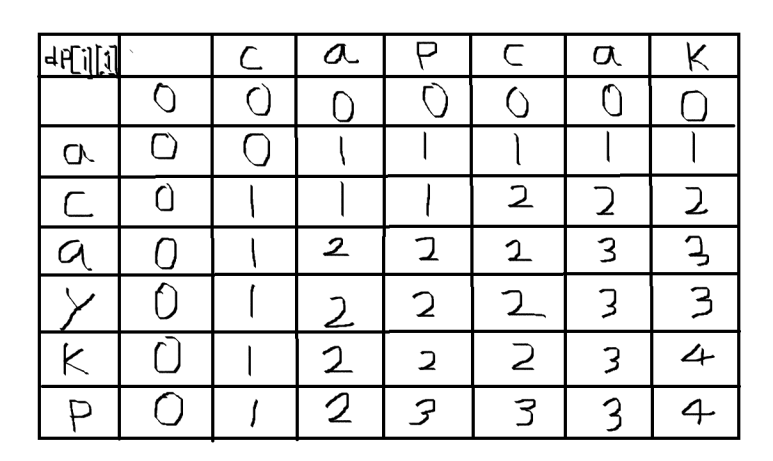
- 두 문자열을 비교하는 표인데 이 때, 반드시 두 문자열의 가장 앞 칸은 0으로 해야 한다.
- 만약 두 문자열 중 어느 것이라도 첫 번째 문자가 일치하면 그 좌표의 -1 좌표에서 값을 참조해야 하는데 [0, 0]이면 앞 칸이기 때문에 음수로 참조하게 되고 에러가 발생한다.
- 최장 공통 부분 수열은 같은 문자를 비교하여, 같은 문자가 있는 좌표에 1을 입력한다. 하지만 Substring과는 다르게 이후의 문자열에 전부 1을 입력해준다. 이 후 겹치는 문자가 있으면 그 부분에 1을 누적 시켜서 쌓아간다.
- 이런 식으로 누적 문자열을 쌓아서 같은 부분의 문자열을 전부 출력한다.
- 최장 공통 부분 수열 점화 식

if i 혹은 j가 0이라면 0이고, i, j > 0 과 x(i) = y(i)가 같다면 하나의 문자가 겹치는 것이기 때문에 c[i][j]는 c[i-1][j-1]에서 +1을 하면 된다.
- 예시 코드
# 최장 공통 부분 수열 함수
def lcs(x, y):
# 두 문자열의 개수를 입력
m = len(x)
n = len(y)
# 문자열 비교 표 생성
l = [[0]*(n+1) for i in range(m+1)]
# 각 첫 줄은 0으로 채우기 위해 (행,열) +1 로 반복
for i in range(m+1):
for j in range(n+1):
# 만약 i가 0이거나 j가 0일 때
if i == 0 or j == 0:
# 좌표에 0을 입력
l[i][j] = 0
# 만약 현재 문자가 서로 같으면
# 처음 인덱스를 생성할 때 첫 줄 0을 위해 +1을 해서 -1을 해줘야 현재값이 나옴
elif x[i-1] == y[j-1]:
# 현재 문자의 값에 +1
l[i][j] = l[i-1][j-1] + 1
# 현재 문자들이 다르면
else:
# 두 문자열 중에 긴 것을 선택한다.
l[i][j] = max(l[i-1][j], l[i][j-1])
# 인덱스에 좌표 집어넣기
index = l[m][n]
# lcs를 저장할 리스트를 생성
lcsword = [""]*index
# 각 문자열의 길이를 i,j에 담고
i = m
j = n
# (맨 끝에서 처음까지 거꾸로 탐색)
# i와 j가 0이 될 때까지
while i > 0 and j > 0:
# 만약 현재 문자가 서로 같으면
if x[i-1] == y[j-1]:
# lcs 해당위치에 문자를 저장시키고 i,j,index를 1씩 감소시킨다.
# (다음문자로 가기위함)
lcsword[index-1] = x[i-1]
i -= 1
j -= 1
index -= 1
# 그게 아니라 현재 위치에서 x와 y의 문자가 다르면 lcs 길이 표에서 이전 위치의 값을 확인해
# 더 큰 값의 방향으로 이동하고 i를 1 감소한다.
elif l[i-1][j] > l[i][j-1]:
i -= 1
# x와 y의 문자가 다르고, y의 이전 문자 방향이 더 클 경우는 j를 1 감소한다.
else:
j -= 1
# 그냥 리턴하면 문자들 사이에 쉼표와 공백이 있기 때문에 join으로 문자들을 다 묶는다.
return "".join(lcsword)
# 문자 두개 입력
x = "ABCBDAB"
y = "BDCAB"
print("LCS of " + x + " and " + y + " is " + lcs(x, y))
학습 시간 : 10 ~ 25시
728x90
'크래프톤 정글 > TIL' 카테고리의 다른 글
| 크래프톤 정글 week03, day21 - 동적 계획법(Dynamic Programming), 연결리스트(Linked-List), 포인터(Pointer) (1) | 2024.02.20 |
|---|---|
| 크래프톤 정글 week03, day20 - 어셈블리어, 오퍼랜드, 점프 인스트럭션, 프로시저 (1) | 2024.02.20 |
| 크래프톤 정글 week03, day18 - 그리디 알고리즘, 분할 정복 (1) | 2024.02.20 |
| 크래프톤 정글 week02, day17 - 알고리즘 문제 (1) | 2024.02.20 |
| 크래프톤 정글 week02, day16 - 이론 공부, 알고리즘 문제 (1) | 2024.02.20 |
