728x90
해시 테이블(Hash Table)
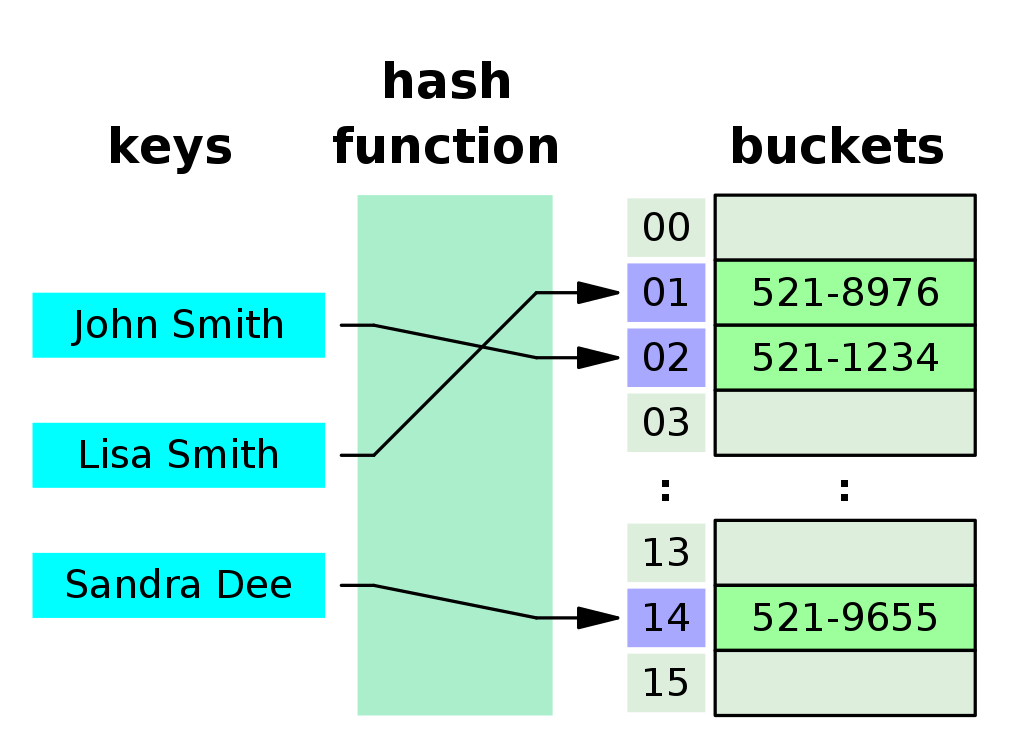
해시 테이블은 키(Key)와 값(Value)을 매핑하여 데이터를 저장하는 데이터 구조 중 하나이며, 이 방식은 빠른 데이터 검색이 가능하다.
하지만, 해시 테이블은 해시 함수를 사용해 저장 위치를 결정하는데, 이 과정에서 충돌(Collision)이 발생할 수 있다.
충돌(Collision)은 두 개의 키가 동일한 해시 값을 가지게 되어, 같은 위치에 저장되려고 할 때 발생하는 상황을 의미하는데 이를 해결하기 위한 몇 가지 방법이 있다.
체이닝(Chaning)
- 충돌을 해결하는 가장 일반적인 방법 중 하나로, 각 해시 테이블의 항목을 연결 리스트로 구성하여 충돌이 발생했을 때, 리스트에 노드를 추가하는 방식이다.
- 이렇게 하면 동일한 해시 값에 대해 여러 키를 저장할 수 있게 된다.
예시)
// 해시테이블
class HashTable {
// 생성자 함수를 정의하고 size만큼의 배열을 생성하고 각 요소를 빈 배열로 매핑한다.
// 이 부분은 해시 충돌을 처리하기 위한 체이닝 방식에서 사용
constructor(size) {
this.buckets = Array(size).fill(null).map(() => []);
}
// key값을 인자로 해당 key의 hash값을 계산한다.
hash(key) {
let hash = 0;
// key의 길이만큼 반복하며 hash에 해당 문자의 유니코드 값을 계속 더한다.
for (let i = 0; i < key.length; i++) {
hash += key.charCodeAt(i);
}
// 최종 hash값에 this.buckets의 길이를 나눈 나머지를 반환한다.
// (결과 값을 인덱스 범위로 매핑하고, 데이터를 균일하게 분산시키기 위함)
return hash % this.buckets.length;
}
// key, value를 인자로 받아 테이블에 저장한다.
set(key, value) {
// key에 대한 해시 값을 계산
const index = this.hash(key);
// 계산된 인덱스에 해당하는 버킷을 할당
const bucket = this.buckets[index];
// 버킷 내에 주어진 key와 일치하는 key-value 쌍을 찾는다.
const found = bucket.find(item => item[0] === key);
// 키가 이미 존재하면 해당 키를 업데이트, 존재하지 않으면 새로운 키값을 버킷에 추가한다.
if (found) {
found[1] = value;
} else {
bucket.push([key, value]);
}
}
// 인자로 받은 key의 값을 조회한다.
get(key) {
// 위 set 함수와 변수를 받는 건 동일
const index = this.hash(key);
const bucket = this.buckets[index];
const found = bucket.find(item => item[0] === key);
// 찾은 경우 found[1]을 반환, 못찾았으면 undefined
return found ? found[1] : undefined;
}
// 인자로 받은 key를 가진 값을 찾아 제거한다.
remove(key) {
const index = this.hash(key);
const bucket = this.buckets[index];
// 주어진 key와 일치하는 요소의 인덱스를 가져온다.
const foundIndex = bucket.findIndex(item => item[0] === key);
// 키를 버킷 내에서 찾았다면 해당 인덱스 위치의 값을 버킷에서 제거하고 true값 반환
if (foundIndex !== -1) {
bucket.splice(foundIndex, 1);
return true;
}
// 못찾았으면 false 반환
return false;
}
}
// 해시테이블 사용
const hashTable = new HashTable(10); // 10개의 배열인 해시테이블을 생성
// 각 key-value값을 해시테이블에 저장하고
hashTable.set("name", "Alice");
hashTable.set("email", "alice@example.com");
hashTable.set("phone", "123-456-7890");
// 각 key의 value값을 출력
console.log(hashTable.get("name")); // Alice
console.log(hashTable.get("email")); // alice@example.com
console.log(hashTable.get("phone")); // 123-456-7890
// key값이 name인 value를 제거하고 그 key값의 value를 출력
hashTable.remove("name");
console.log(hashTable.get("name")); // 이미 제거했으니 undefined
재해싱(Rehashing)
- 해시 테이블의 저장 공간이 부족하게 되거나, 충돌이 너무 자주 발생하는 경우, 해시 테이블의 크기를 조정하고 모든 항목을 새로운 크기에 맞게 다시 해싱하는 과정이다.
- 이는 해시 테이블의 성능을 유지하기 위해 필요한 작업이며 재해싱은 새로운 해시 함수를 사용하거나, 해시 테이블의 크기를 늘리는 방식으로 수행될 수 있다.
예시)
// 해시테이블
class HashTable {
// 해시테이블 생성자
constructor(size = 8) {
this.buckets = Array(size).fill(null).map(() => []); // 8인 배열을 null로 채운 버킷 생성
this.size = size; // 해시 테이블의 초기 크기 설정
this.itemCount = 0; // 해시 테이블에 저장된 항목 수를 0으로 초기화
}
// 작성 함수들은 itemCount를 사용한 코드 외 위 체이싱과 거의 동일
hash(key) {
let hash = 0;
for (let i = 0; i < key.length; i++) {
hash += key.charCodeAt(i);
}
return hash % this.size;
}
set(key, value) {
// 로드 팩터가 0.75를 초과하면 재해싱
if (this.loadFactor() > 0.75) {
this.rehash();
}
const index = this.hash(key);
const bucket = this.buckets[index];
const found = bucket.find(item => item[0] === key);
if (found) {
found[1] = value;
} else {
bucket.push([key, value]);
this.itemCount++; // 항목 추가 시 itemCount 증가
}
}
get(key) {
const index = this.hash(key);
const bucket = this.buckets[index];
const found = bucket.find(item => item[0] === key);
return found ? found[1] : undefined;
}
remove(key) {
const index = this.hash(key);
const bucket = this.buckets[index];
const foundIndex = bucket.findIndex(item => item[0] === key);
if (foundIndex !== -1) {
bucket.splice(foundIndex, 1);
this.itemCount--; // 항목 제거 시 itemCount 감소
return true;
}
return false;
}
// 로드팩터를 계산한다.
// 로드팩터 : 해시 테이블에 저장된 항목 수를 버킷의 수로 나눈 값
loadFactor() {
return this.itemCount / this.size;
}
// 해시 테이블의 크기를 조정하고 모든 항목을 새로운 버킷에 재배치하는 함수
// 해시 테이블의 크기를 현재 크기의 두 배로 증가시킨다.
rehash() {
const oldBuckets = this.buckets;
this.size = this.size * 2; // 버킷의 크기를 두 배로 증가
this.buckets = Array(this.size).fill(null).map(() => []);
this.itemCount = 0; // 재해싱 과정에서 항목 수 재계산
oldBuckets.forEach(bucket => {
bucket.forEach(([key, value]) => {
this.set(key, value); // 모든 항목을 새로운 버킷 크기에 맞게 재삽입
});
});
}
}
// 해시테이블 사용 예제
const hashTable = new HashTable(4); // 초기 크기를 작게 설정하여 재해싱 발생을 쉽게 확인
// 해시테이블에 key-value 항목을 저장
hashTable.set("name", "Alice");
hashTable.set("email", "alice@example.com");
hashTable.set("phone", "123-456-7890");
hashTable.set("address", "Seoul");
// 각 key의 value값을 출력
console.log(hashTable.get("name")); // Alice
console.log(hashTable.get("email")); // alice@example.com
console.log(hashTable.get("phone")); // 123-456-7890
console.log(hashTable.get("address")); // Seoul
이러한 방법들을 통해 해시 테이블은 데이터의 빠른 접근, 삽입 및 삭제 등의 연산을 효율적으로 수행할 수 있다.
각 방법은 상황에 따라 그 성능과 효율성이 달라지므로, 구현 시에는 해시 테이블의 사용 목적과 환경을 고려하여 적절한 방법을 선택해야 한다.
728x90
'공부 키워드 > 알고리즘 및 데이터 구조' 카테고리의 다른 글
| 그래프(Graph) (1) | 2024.04.03 |
|---|---|
| 깊이 우선 탐색(DFS, depth-first search), 너비 우선 탐색(BFS, Breadth-first search) (0) | 2024.04.02 |
| Deep Copy vs Shallow Copy (1) | 2024.03.31 |
| 스택(Stack), 큐(Queue) (3) | 2024.03.29 |
| 연결 리스트(Linked List) (1) | 2024.03.29 |


