캐시 메모리
캐시 메모리는 어디에 위치해 있나요?
캐시 메모리는 컴퓨터 시스템에서 매우 중요한 역할을 하는 고속 메모리로, CPU와 주 메모리(RAM) 사이에 위치해 있다.
일반적으로 캐시 메모리는 세 가지 계층으로 나눌 수 있다.
- L1 캐시 (Level 1 Cache)
- L1 캐시는 CPU 코어 내부에 위치해 있으며, 데이터 캐시와 명령어 캐시로 나뉠 수 있다.
- 각 코어마다 별도의 L1 캐시가 존재하며, 가장 작은 크기(일반적으로 수십 KB)지만 가장 빠른 속도를 가진다.
- L2 캐시 (Level 2 Cache)
- L2 캐시는 일반적으로 각 CPU 코어마다 별도로 존재하지만, L1 캐시보다는 크기가 크고(일반적으로 수백 KB에서 수 MB) 속도는 조금 느리다.
- 일부 CPU 아키텍처에서는 L2 캐시가 모든 코어가 공유하는 구조로 되어 있을 수도 있다.
- L3 캐시 (Level 3 Cache)
- L3 캐시는 모든 CPU 코어가 공유하는 구조로 되어 있으며, 가장 큰 크기(수 MB에서 수십 MB)를 가지지만 L1 및 L2 캐시보다는 느리다.
- L3 캐시는 반도체 칩인 CPU 다이(die) 내부에 존재하거나, 경우에 따라 다이 외부에 위치할 수도 있다.
이와 같이 캐시 메모리는 CPU 내부와 매우 가까운 위치에 있어 주 메모리보다 훨씬 빠르게 데이터에 접근할 수 있게 해준다.
L1, L2 캐시에 대해 설명해 주세요.
L1 캐시 (Level 1 Cache)
- 위치: 각 CPU 코어에 내장되어 있다.
- 크기: 일반적으로 수십 KB (32KB에서 128KB 정도).
- 속도: 가장 빠른 캐시로, CPU 클럭 속도와 거의 같은 속도로 동작한다.
- 구성: 일반적으로 두 부분으로 나뉜다.
- L1 데이터 캐시 (L1 Data Cache): 데이터를 저장
- L1 명령어 캐시 (L1 Instruction Cache): 명령어를 저장
- 역할: 가장 자주 사용되는 데이터와 명령어를 저장하여 CPU가 빠르게 접근할 수 있도록 한다. 캐시 미스가 발생하면 더 낮은 계층의 캐시나 주 메모리에서 데이터를 가져온다.
L2 캐시 (Level 2 Cache)
- 위치: CPU 코어 내에 있거나 코어와 별도로 위치할 수 있다. 대부분의 현대 CPU에서는 각 코어마다 독립적인 L2 캐시가 존재한다.
- 크기: 일반적으로 수백 KB에서 수 MB (256KB에서 8MB 정도).
- 속도: L1 캐시보다는 느리지만 매우 빠르다.
- 구성: 데이터와 명령어를 모두 저장하는 통합된 구조를 가질 수 있다.
- 역할: L1 캐시에서 캐시 미스가 발생했을 때 데이터를 제공하여 CPU 성능을 향상시킨다. L2 캐시 미스가 발생하면 L3 캐시나 주 메모리에서 데이터를 가져온다.
캐시간의 동기화는 어떻게 이루어지나요?
캐시 메모리의 동기화는 멀티코어 CPU에서 각 코어의 캐시 메모리가 일관된 상태를 유지하도록 하는 중요한 작업이다.
그렇기 때문에, 캐시 동기화는 캐시 일관성(caching consistency)을 보장하기 위해 다양한 기술과 프로토콜을 사용하는데, 이 과정은 주로 캐시 일관성 프로토콜(cache coherence protocol)을 통해 이루어진다.
캐시 일관성 프로토콜
캐시 일관성 프로토콜은 멀티코어 시스템에서 캐시 메모리 간의 데이터 일관성을 유지하기 위한 규칙과 메커니즘을 제공한다.
대표적인 프로토콜
MESI 프로토콜
MESI는 가장 널리 사용되는 캐시 일관성 프로토콜 중 하나로, 각 캐시 라인은 다음 네 가지 상태 중 하나를 가질 수 있다.
- Modified (M): 캐시 라인이 변경되었으며, 이 데이터는 현재 캐시에만 있고 주 메모리에는 반영되지 않은 상태
- Exclusive (E): 캐시 라인이 변경되지 않았으며, 이 데이터는 현재 캐시에만 있고 다른 캐시에는 없는 상태
- Shared (S): 캐시 라인이 다른 캐시에도 존재할 수 있으며, 변경되지 않은 상태
- Invalid (I): 캐시 라인이 유효하지 않은 상태
이 프로토콜은 캐시의 상태 변화를 통해 동기화를 관리하며, 필요한 경우 캐시 간에 데이터를 전달하거나 주 메모리와 동기화한다.
동기화 메커니즘
캐시 동기화는 여러 가지 메커니즘을 통해 이루어진다.
- 버스 스누핑 (Bus Snooping)
- 각 캐시 컨트롤러가 시스템 버스를 감시하여 다른 캐시가 주고받는 데이터를 모니터링한다.
- 이 방법을 통해 캐시는 다른 캐시의 데이터 변경을 인식하고 자신의 데이터를 업데이트하거나 무효화한다.
- 디렉토리 기반 프로토콜 (Directory-Based Protocol)
- 중앙 디렉토리를 사용하여 캐시 라인의 상태를 추적한다.
- 각 캐시의 상태 변화가 디렉토리에 기록되며, 이 디렉토리가 다른 캐시에 데이터를 전달하거나 동기화를 관리하는데, 이는 버스 스누핑보다 확장성이 좋다.
- 인밸리데이션 (Invalidation)
- 한 캐시가 데이터 변경을 수행하면, 그 데이터가 다른 캐시에 존재할 경우 해당 캐시 라인을 무효화한다.
- 이는 다른 캐시가 더 이상 이 데이터를 사용하지 못하게 하여 일관성을 유지한다.
- 업데이트 (Update)
- 데이터가 변경되면 그 데이터를 다른 캐시에 업데이트한다.
- 이는 인밸리데이션 방식과 반대로, 모든 캐시에 동일한 데이터를 유지하도록 한다.
예시
- CPU 코어 A가 데이터를 수정: CPU 코어 A가 캐시된 데이터를 수정하면, 그 데이터의 상태는 "Modified"로 변경된다.
- CPU 코어 B가 동일한 데이터에 접근: CPU 코어 B가 동일한 데이터에 접근하려고 하면, 버스 스누핑 메커니즘이 이를 감지하고 CPU 코어 A의 캐시를 인밸리데이트하거나 데이터를 전달받아 "Shared" 상태로 변경한다.
- 메모리에 반영: "Modified" 상태의 데이터는 나중에 주 메모리에 기록되어 메모리와 일관성을 유지한다.
캐시의 지역성을 기반으로, 이차원 배열을 가로/세로로 탐색했을 때의 성능 차이에 대해 설명해 주세요.
캐시 메모리의 성능은 데이터 접근 패턴, 특히 지역성 원칙에 크게 의존한다.
지역성은 주로 두 가지 종류가 있는데, 시간적 지역성(Temporal Locality)과 공간적 지역성(Spatial Locality)이 있다.
이차원 배열을 탐색할 때 가로(행)와 세로(열) 탐색은 캐시의 지역성 원칙에 따라 성능 차이를 보인다.
가로 탐색 (행 우선 탐색)
const rows = 4;
const cols = 4;
const array = [
[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12],
[13, 14, 15, 16]
];
for (let i = 0; i < rows; i++) {
for (let j = 0; j < cols; j++) {
console.log(array[i][j]); // 배열 원소에 접근
}
}성능 분석
- 공간적 지역성
- 행 우선 탐색에서는 배열의 인접한 요소들이 연속적으로 메모리에 저장되므로, 하나의 캐시 라인이 로드될 때 그 캐시 라인 내의 여러 요소들이 함께 캐시에 적재된다.
- 이는 공간적 지역성을 잘 활용하는 방식이다.
- 캐시 적중률
- 연속된 메모리 주소에 접근하므로, 캐시 적중률이 높아져 성능이 향상된다.
세로 탐색 (열 우선 탐색)
const rows = 4;
const cols = 4;
const array = [
[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12],
[13, 14, 15, 16]
];
for (let j = 0; j < cols; j++) {
for (let i = 0; i < rows; i++) {
console.log(array[i][j]); // 배열 원소에 접근
}
}성능 분석
- 공간적 지역성
- 열 우선 탐색에서는 인접한 메모리 주소에 접근하지 않으므로, 각 열의 요소들이 서로 멀리 떨어져 있다.
- 이는 공간적 지역성을 잘 활용하지 못하는 방식이다.
- 캐시 미스율
- 배열의 각 요소들이 서로 멀리 떨어져 있어, 캐시 라인이 자주 변경된다.
- 이는 캐시 미스율을 높여 성능이 저하된다.
성능 차이 설명
- 가로 탐색 (행 우선 탐색)
- 배열을 행 단위로 순차적으로 접근한다.
- 이는 메모리 레이아웃에서 연속된 메모리 블록에 접근하므로 캐시 효율성이 높다.
- 세로 탐색 (열 우선 탐색)
- 배열을 열 단위로 접근한다.
- 이는 메모리에서 비연속적인 위치에 접근하므로 캐시 미스가 발생할 가능성이 높고, 따라서 성능이 저하될 수 있다.
동일한 데이터 구조를 탐색하더라도 접근 패턴에 따라 성능 차이가 발생할 수 있다는 것을 알 수 있으며, 일반적으로 이차원 배열을 다룰 때는 연속적인 위치로 접근하는 가로 탐색이 더 효율적이다.
랜선 자르기

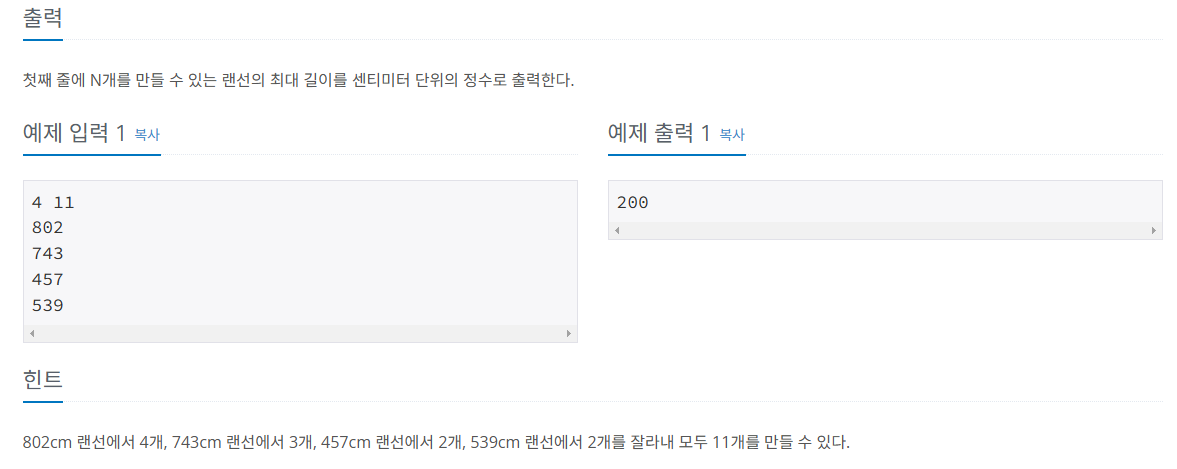
코드)
a, b = map(int, input().split())
arr = []
start = 1
for i in range(a):
arr.append(int(input()))
long = max(arr)
while start <= long:
lanport = 0
mid = (start + long) // 2
for i in range(len(arr)):
lanport += arr[i]//mid
if lanport >= b:
start = mid + 1
else:
long = mid-1
print(long)'개발 TIL' 카테고리의 다른 글
| 24.07.18 day28 가상 메모리 (0) | 2024.07.18 |
|---|---|
| 24.07.17 day27 메모리 연속할당, 숫자 고르기 (0) | 2024.07.17 |
| 24.07.15 day25 IPC, CSR과 SSR (0) | 2024.07.15 |
| 24.07.12 day24 남추문 스터디 회고 (0) | 2024.07.12 |
| 24.07.11 day23 뮤텍스와 세마포어, 데드락(Deadlock), 프로그램 컴파일 (0) | 2024.07.11 |

